In a DNS zone, every record carries its own time-to-live, so that it can be cached, yet still changed if necessary.
This information is originally served by authoritative servers for the related zone. The TTL is represented as an integer number of seconds.
At first sight, the mechanism looks straightforward: if the
www.example.com record has a TTL of 30, it’s only valid up to 30
second, and caches must fetch it again if requested after this delay.
Chained caches
DNS caches can be chained: instead of directly querying authoritative servers, a cache can forward queries to a another server, and cache the result.
Having 3 or 4 chained caches is actually very common. Web browsers, operating systems and routers can cache and forward DNS a query. Eventually, this query will be sent to an upstream cache, like the ISP cache or a third-party service like OpenDNS. And these caches can also actually hide multiple chained caches.
In order to respect the original TTL, caches are modifying records as they forward them to clients. The response to a query that has been sitting in a cache for 10 second will be served with a TTL reduced by 10 second. That way, if the original TTL was 30 second, the whole chain is guaranteed to consider this record as expired as the same time: the original meaning of the TTL is retained no matter how many resolvers there are in the way.
Well, not exactly. A TTL is just a time interval, not an absolute date. Unlike a HTTP response, a DNS response doesn’t contain any timestamp. Thus, requests processing and network latency are causing caches to keep a record longer than they actually should in order to respect the initial TTL.
A TTL being an integer value makes things even worse: a chain of N caches can introduce a N second bias.
In practice, this is rarely an issue: TTLs as served by authoritative servers are considered indicative, and not as something to depend on when accurate timing is required.
The decay of a TTL, as seen by different pieces of software
How does the TTL of a record served by a DNS cache decays over time?
Surprisingly, different implementations exhibit different behaviors.
For a record initially served with a TTL equal to N by authoritative servers:
- Google DNS serves it with a TTL in the interval [0, N-1]
- dnscache is serving it with a TTL in the interval [0, N]
- Unbound serves it with a TTL in the interval [0, N]
- Bind serves it with a TTL in the interval [1, N]
- PowerDNS Recursor always serves it with a TTL of N
Hold on… Does it mean that how frequently an entry will actually be refreshed depends on what software resolvers are running?
Sadly, yes. Given a record with a TTL equal to N:
- Bind and PowerDNS Recursor refresh it every N second if necessary
- Unbound and dnscache are only refreshing it every N + 1 seconds at best.
TTL Zero
Although a TTL of zero can cause interoperability issues, most DNS caches are considering records with a TTL of zero as records that should not be cached.
This perfectly makes sense when the TTL of zero is the original TTL, as served by authoritative servers.
However, when a cache artificially changes the TTL to zero, it changes a record that had been designed for being cached to an uncachable record that contaminates the rest of the chain.
dnscache and a 1 second record
To illustrate this, a Linux box has been setup with a local DNS cache. Unbound has been chosen, but the last component of the chain actually makes little difference. Even web browsers caches have a very similar behavior.
Queries are forwarded to an upstream cache on the same LAN, running dnscache, and outgoing queries are recorded with ngrep. The same query, whose response has a TTL of 1, is made at a 10 queries per second rate.
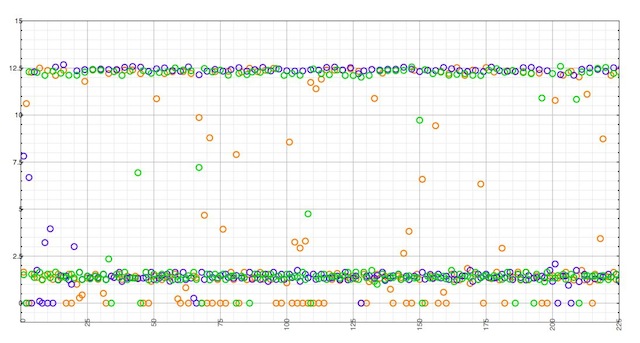
The X axis represents outgoing queries, whereas the Y axis is the time elapsed since the previous query.
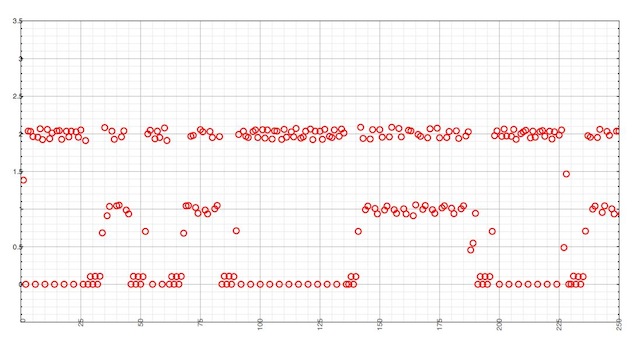
Even though a TTL of 1 is served by authoritative servers for this record, a large amount of responses are cached and served for 2 second. This is due to the local Unbound resolver.
However, there is also quite a lot of responses that haven’t been cached at all. It happens when dnscache serves a response with a TTL of 0. Since it happens one third of the time, this is suboptimal and not on par with the intent of the authoritate record, which is served with non-zero TTL.
And although dnscache and Unbound are handling TTLs the same way, we can’t expect their caches to be perfectly synchronized. When the local cache considers a record as expired and issues an outgoing query, the upstream server can consider it as not expired yet, just in the middle of the last second. What we get is a constant race between caches, causing jitter and outgoing queries sent after 1 second.
How different implementations can affect the number of outgoing queries
The following experiment has been made by observing outgoing queries when sending 10,000 queries for a record with a TTL of 2, at an average 10 qps rate, to a local cache, using Google, OpenDNS and Level 3 as upstream resolvers.
Here is the number of outgoing queries that were required to complete the 10,000 local queries using different services:
| Service | Outgoing queries |
|---|---|
| Google DNS | 1383 |
| OpenDNS | 632 |
| Level 3 | 388 |
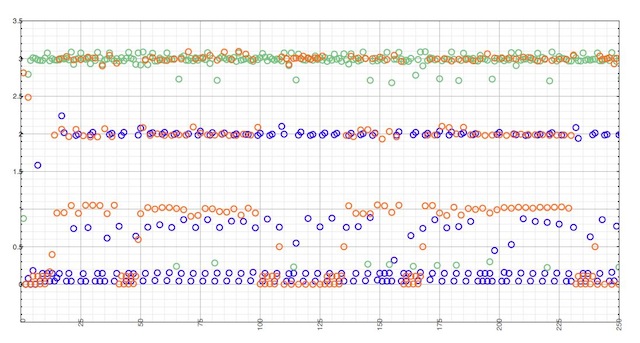
When using Google DNS (blue dots), queries are effectively never cached more than 2 second, even locally. This is due to the max TTL returned by Google DNS being the initial TTL minus one.
When Google DNS returns a TTL of zero, we observe the same jitter and the same slew of queries that couldn’t be served from the local cache.
OpenDNS (orange dots) has the same behavior as dnscache and Unbound., with TTLs in the [0, N] interval. Our initial TTL with a value of 2 actually causes 3, 2, and 1 second delays between request, plus a sensitive amount of consecutive outgoing queries due a null TTL.
Level 3 (green dots) is running Bind, which returns a TTL in the [1, N] interval. Bind caches records one second less than dnscache and Unbound. Because our local resolver is Unbound, queries received with a TTL of N are actually cached N + 1 second. But as expected, the frequency of required outgoing queries very rarely exceeds 3 second.
What the correct behavior is, is out of scope of this article. All major implementations are probably correct.
But from a user perspective, with only 2 caches in the chain, and for a given record, the same set of queries can require up to 3.5 more outgoing queries to get resolved, depending on what software the remote cache is running.
With CDNs and popular web sites having records with a very low TTL (Facebook has a 30 second TTL, Skyrock has a 10 second TTL), the way a cache handles TTLs can have a sensible impact on performance. That said, some resolvers can be configured to pre-fetch records before they expire, effectively mitigating this problem.
Update: OpenDNS resolvers now behave like Bind: TTLs are now in the [1, N] interval.
The OSX cache
MacOS X provides a system-wide name cache, which is enabled by default.
Its behavior is quite surprising, though. It seems to enforce a minimum TTL of 12.5 seconds, while still requiring some outgoing queries delayed by the initial TTL value, and some consecutive ones. Resolving the 10,000 queries from the previous test took only an average of 232 outgoing queries.
Using Google DNS, OpenDNS and Level 3 as a remote resolver produce the same result, with the exception on Level 3 (Bind) avoiding frequent (less than 1 sec) consecutive queries during the time other return a TTL of zero.