I wanted to know if WebAssembly runtimes are getting faster.
This is a follow-up to the earlier libsodium WebAssembly benchmarks from 2019, 2021 and 2023.
Not “does the newest version beat native code in one microbenchmark?”, and not “which runtime has the prettiest benchmark chart?”, but something more boring and more useful:
If I take the same C crypto code, compile it to WebAssembly, and run it on the latest runtime, a runtime from one year ago, and a runtime from two years ago, are things actually improving?
So I benchmarked libsodium on WebAssembly runtimes released around June 2024, June 2025, and June 2026.
The short version:
wasmeris the best performer, butWAVM,WAMRandWasmtimeare close.WAVMhas the best optimizer, and is able to generate very fast code out from baseline, portable WebAssembly- The new WebAssembly
wide_arithmeticinstructions are a big deal for crypto code when runtimes support them.
What I measured
The test program is libsodium’s benchmark suite, built from libsodium commit 8e3be8615ba6adcd7babaecf5e76f516890ba5fb.
I built one native baseline and several WebAssembly variants:
- native x86-64, compiled with Zig using the local CPU target
- plain WebAssembly
- WebAssembly with
lime1 - WebAssembly with
lime1andsimd128 - WebAssembly with
lime1,simd128, andwide_arithmetic
For the native reference, libsodium was built with -Dcpu=native. For wasm2c, the generated C was compiled with zig cc -O3 -march=native.
For WAMR, I used AOT mode: wamrc compiled each .wasm file to an .aot file, and iwasm ran the resulting AOT file. wamrc doesn’t accept --cpu=native, so I used --target=x86_64 --cpu=x86-64-v4 --opt-level=3, which matches the host’s available x86-64 feature level and works across the WAMR versions that could compile these modules.
The native command was:
zig build -Denable_benchmarks -Doptimize=ReleaseFast -Dcpu=native -Diterations=3
The WebAssembly commands were the same shape, with a wasm32-wasi target and the feature-specific CPU strings:
zig build -Denable_benchmarks -Dtarget=wasm32-wasi -Doptimize=ReleaseFast -Diterations=3
zig build -Denable_benchmarks -Dtarget=wasm32-wasi -Doptimize=ReleaseFast -Dcpu=lime1 -Diterations=3
zig build -Denable_benchmarks -Dtarget=wasm32-wasi -Doptimize=ReleaseFast -Dcpu=lime1+simd128 -Diterations=3
zig build -Denable_benchmarks -Dtarget=wasm32-wasi -Doptimize=ReleaseFast -Dcpu=lime1+simd128+wide_arithmetic -Diterations=3
The host was an AMD Ryzen AI 9 HX 470 with 12 cores and 24 threads. CPU boost was disabled and the maximum CPU frequency was 2 GHz. The OS was Linux 7.1.0-rc7, and Zig was 0.17.0-dev.948+e949341b7.
The numbers below are the geometric mean of per-benchmark slowdowns relative to the native build. Lower is better. A value of 2.0 means “twice as slow as native” on this machine.
I used ITERATIONS=3, so the very small libsodium tests are noisy and quantized. Rows reporting zero time were excluded from the aggregate.
Versions
For every runtime except WAVM, I used the latest stable release available on June 23, 2026, plus a stable release from roughly one year earlier and one from roughly two years earlier.
| Runtime | 2024 | 2025 | 2026 |
|---|---|---|---|
Bun |
1.1.16 |
1.2.17 |
1.3.14 |
Node |
22.3.0 |
24.2.0 |
26.3.1 |
WAMR |
2.1.0 |
2.3.1 |
2.4.4 |
WABT wasm2c |
1.0.35 |
1.0.37 |
1.0.41 |
WasmEdge |
0.14.0 |
0.14.1 |
0.17.0 |
Wasmer |
4.3.2 |
6.0.1 |
7.1.0 |
Wasmtime |
22.0.0 |
34.0.0 |
46.0.0 |
WAVM |
n/a |
n/a |
nightly/2026-04-05 |
Wazero |
1.7.3 |
1.9.0 |
1.12.0 |
WAVM is awkward to compare historically. The old available nightly collapsed to a 2022 binary for both the 2024 and 2025 slots, and that binary refused to run on this machine. I only kept the 2026 nightly.
WAMR 2.1.0, the selected 2024 release, installed fine but its AOT compiler failed on these Zig-generated modules with invalid WASM stack data type. I kept the version in the matrix, but didn’t include an aggregate for it.
Baseline WebAssembly
This is the plain WebAssembly build, without lime1, SIMD, or wide arithmetic.
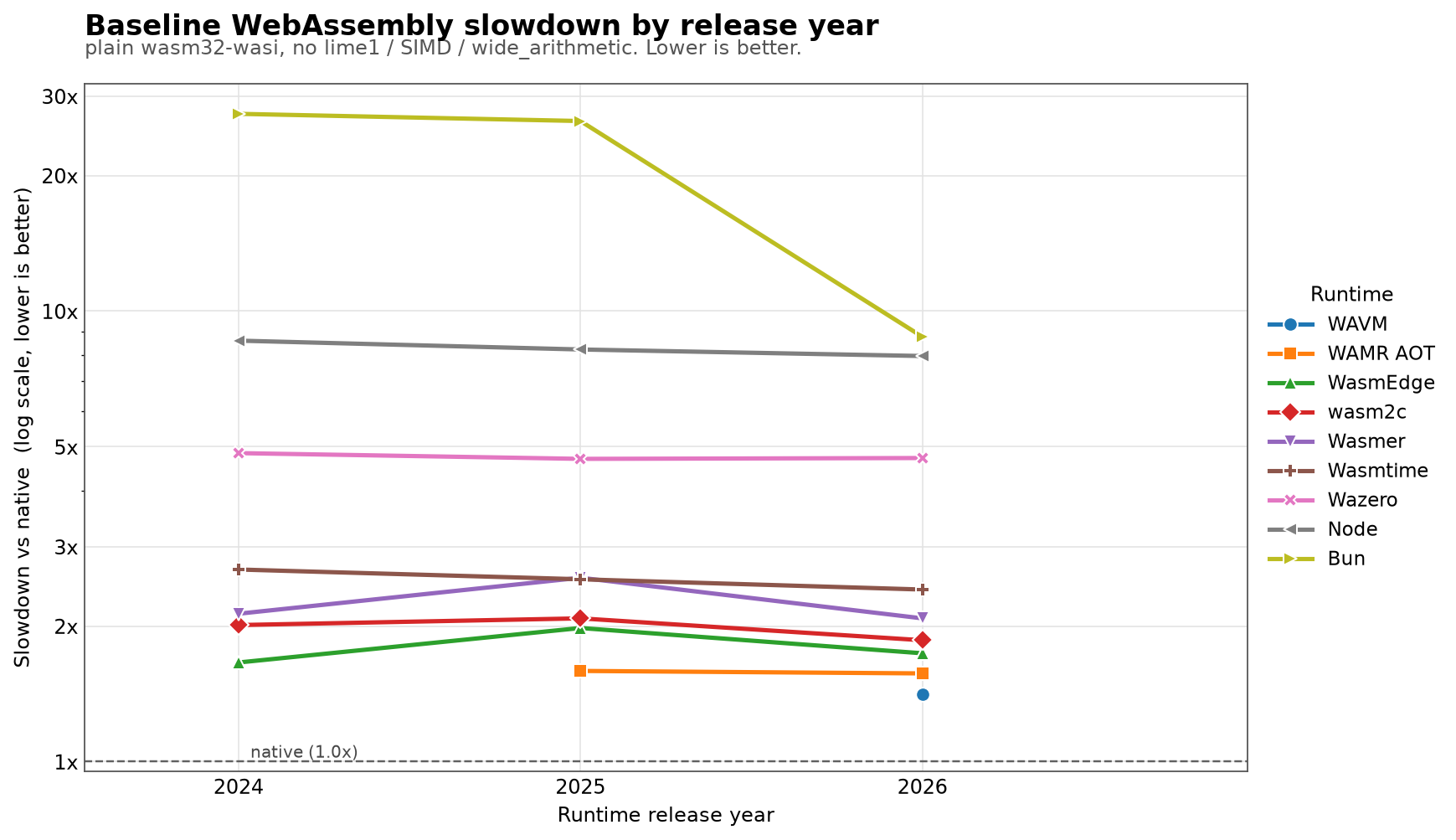
There isn’t one universal trend.
Wasmtime steadily improved: 2.67x native in 2024, 2.54x in 2025, 2.41x in 2026. It got faster every year, and the gains land in the tenths place, above the noise.
Node also improved slowly, from 8.60x native to 7.95x native.
Wazero was basically flat: 4.84x, 4.70x, 4.72x native. No real movement over two years.
WAMR in AOT mode was already fast in 2025 and stayed there in 2026: 1.59x native, then 1.57x native, the same within this benchmark’s noise. I don’t have a complete 2024 WAMR number because WAMR 2.1.0 couldn’t compile these modules.
Wasmer regressed in the 2025 release I tested, then recovered in 2026. The 2026 baseline barely beats 2024.
wasm2c improved modestly in 2026. It remains one of the best options if ahead-of-time translation to native C is acceptable for your deployment model.
Bun is the outlier. Its 2024 and 2025 results were far behind, but the 2026 result is about three times faster than the 2025 result. It’s still slower than Node on this benchmark, but the direction is excellent.
WasmEdge is fast too, but its command-line behavior changed enough to matter. My first 0.17.0 run accidentally used interpreter mode for compiled modules and looked catastrophically slow. Running the compiled modules with --run-mode=aot fixed it: the 2026 baseline was 1.74x native, between the 2024 and 2025 baseline results.
Best supported build by year
The baseline table is useful because it compares the same WebAssembly target everywhere.
But if you’re choosing a runtime for your own deployment, you probably care about the fastest build that runtime can actually run.
So for each runtime and year, I also selected the best complete result among the supported builds: baseline, lime1, lime1+simd128, and lime1+simd128+wide_arithmetic.
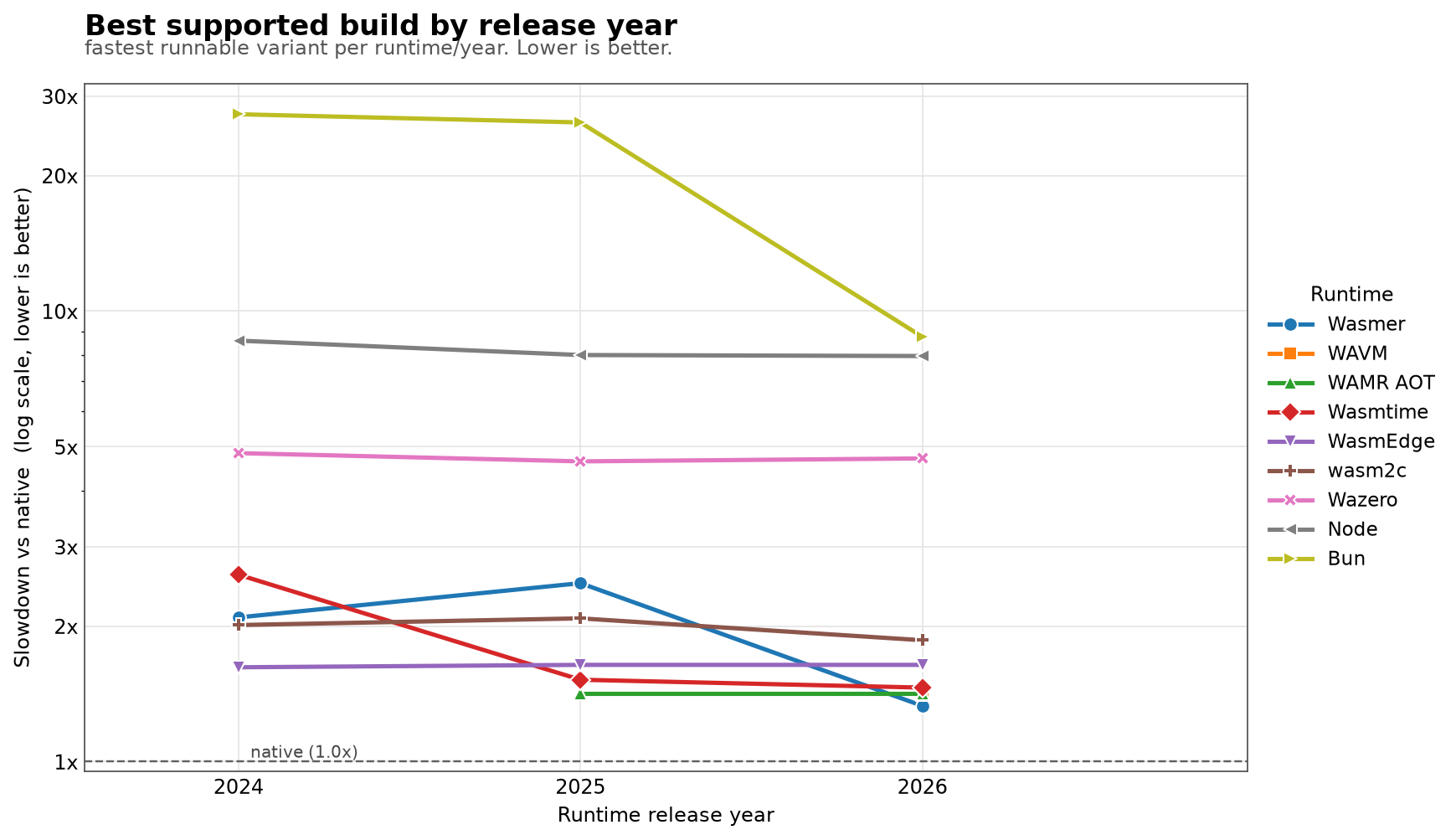
Looks similar to the previous graph, except for Wasmtime and Wasmer that really benefit from wide_arithmetic.
Ranked by the best supported build, the complete current-year results are:
![]()
CPU feature variants
The WebAssembly feature story is more interesting than the year-to-year runtime story.
For the 2026 releases, these were the aggregate slowdowns:
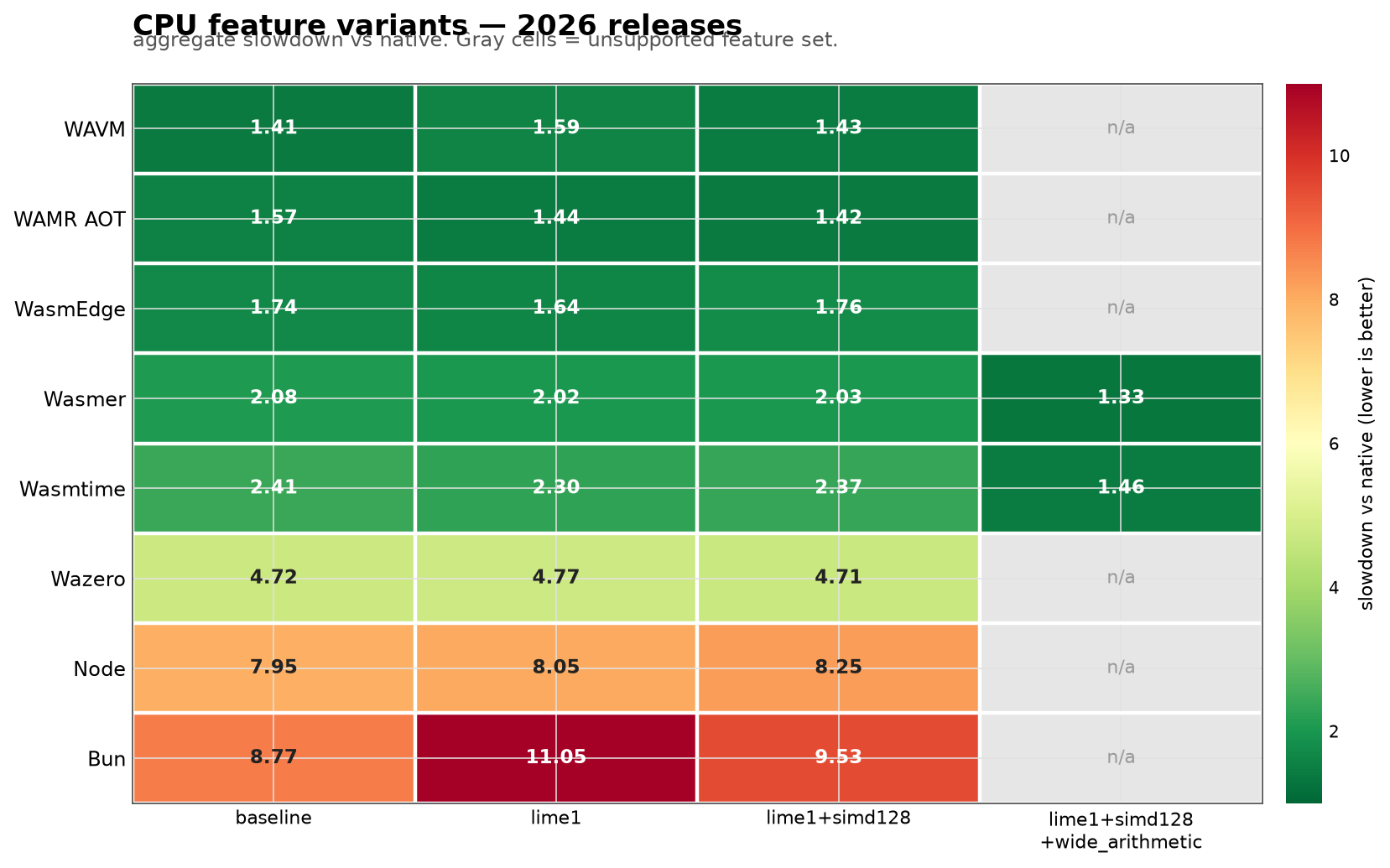
lime1 and simd128 alone aren’t magic here. Sometimes they help, sometimes they hurt, and sometimes the difference is lost in benchmark noise.
wide_arithmetic is different.
Only Wasmtime and Wasmer could run the full wide_arithmetic build among the complete stable rows I tested. WAMR rejected it with unsupported opcode 0xfc13. But when wide_arithmetic worked, it was the biggest speedup in the whole experiment:
Wasmtime 46.0.0: 2.41x native without it, 1.46x native with it.Wasmer 7.1.0: 2.08x native without it, 1.33x native with it.
That’s the kind of change I like. A lot of libsodium’s expensive operations are arithmetic-heavy. If the WebAssembly ISA can express that arithmetic directly, the runtime has much less work to rediscover what the C compiler already knew.
Failures
Most runs completed cleanly, but not all of them.
Bun 1.2.17 failed box_easy in the baseline build. Bun 1.1.16 failed pwhash_argon2i in the lime1 and lime1+simd128 builds.
Node 22.3.0 originally failed pwhash_argon2i, pwhash_argon2id, and pwhash_scrypt in the baseline, lime1, and lime1+simd128 builds. The failures weren’t fixed by increasing Node’s JavaScript heap or stack settings. They were fixed by giving the Wasm modules an explicit maximum linear memory. With the baseline build, a 1024-page maximum, or 64 MiB, made pwhash_argon2i, pwhash_argon2id, and pwhash_scrypt complete. But pwhash_scrypt failed with 512 pages and segfaulted again at 1536 pages and above, so this appears to be a V8 memory-mode threshold rather than a simple “more memory is better” setting.
WAMR 2.1.0, the 2024 slot, couldn’t compile even the baseline modules in AOT mode. WAMR 2.3.1 and 2.4.4 compiled and ran the baseline, lime1, and lime1+simd128 builds, but not wide_arithmetic.
Those failures were excluded from the aggregate. So were benchmark rows with a zero reported median.
So, are runtimes getting faster?
Some of them are.
Wasmtime is the cleanest yes: it got faster every year in this benchmark, by a little each time.
Node is also a yes, but the slope is gentle.
Bun is a loud yes between 2025 and 2026. It still has a lot of ground to cover for this workload, but the improvement is too large to ignore.
Wazero is mostly flat.
WAMR is also mostly flat between the versions that worked here, but “flat” at about 1.4x to 1.6x native is a very good place to be.
Wasmer is mixed if you only look at the baseline, but the 2026 release supporting wide_arithmetic changes the practical answer for crypto code. With that feature enabled, it was the fastest complete 2026 result I could compare across a normal current release.
wasm2c remains good. If you can translate WebAssembly to C ahead of time and compile it for the host, it’s hard to beat.
WAVM produced the fastest 2026 baseline number, but I don’t have a fair 2024 or 2025 comparison.
WasmEdge remains excellent once it’s forced into AOT mode. The accidental interpreter-mode run was a good reminder that command-line defaults are part of the benchmark, too.
Takeaways
If you run CPU-heavy cryptography in WebAssembly, runtime choice still matters a lot.
The spread between the fastest complete current result and the slowest current result is large: Wasmer with wide_arithmetic was 1.33x native, while current Bun baseline was 8.77x native.
Feature support matters too. The same runtime can move from “pretty good” to “surprisingly close to native” when the WebAssembly module can use better arithmetic instructions.
The comforting part is that the mainstream runtimes aren’t standing still. Wasmtime improved steadily. Bun made a huge jump. Wasmer gained a feature that matters for real crypto workloads. WasmEdge remained fast once the AOT run mode was explicit.
The less comforting part is that WebAssembly performance still isn’t one thing. It depends on the runtime, the release, the enabled WebAssembly features, whether the code goes through WASI from JavaScript, and whether ahead-of-time native compilation is allowed.
So benchmark your actual workload.
But if your workload looks like libsodium, the answer in 2026 is: WebAssembly can be close to native, wide_arithmetic is worth caring about, and yes, some runtimes really are getting faster.