DNS latency is a key component to having a good online experience. And in order to minimize DNS latency, carefully picking DNS servers and anonymization relays play an important role. But the best way to minimize latency is to avoid sending useless queries to start with.
Which is why DNS was designed since day one to be a heavily cacheable protocol. Individual records have a time-to-live, originally set by zone administrators, and resolvers use this information to keep these records in memory in order to avoid unnecessary traffic.
Is caching efficient? A quick study I made a couple years ago showed that there was room for improvement. Today, I wanted to take a new look at the current state of affairs.
In order to do so, I patched Encrypted DNS Server to store the original TTL of a response, defined as the minimum TTL of its records, for each incoming query. This gives us a good overview of the TTL distribution of real-world traffic, but also accounts for the popularity of individual queries. That patched version was left to run for a few hours.
The resulting data set is composed of 1,583,579 (name, qtype, TTL, timestamp) tuples. Here is the overall TTL distribution (the X axis is the TTL in seconds):
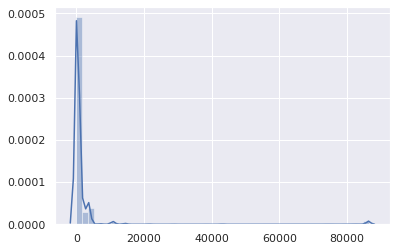
Besides a negligible bump at 86400 (mainly for SOA records), it’s pretty obvious that TTLs are in the low range. Let’s zoom in:
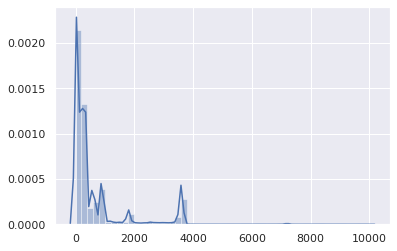
Alright, TTLs above 1 hour are statistically insignificant. Let’s focus on the 0-3600 range, then:
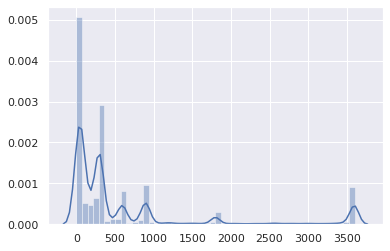
And where most TTLs sit, between 0 and 15 minutes:
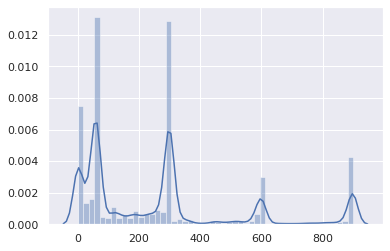
The vast majority is between 0 and 5 minutes:
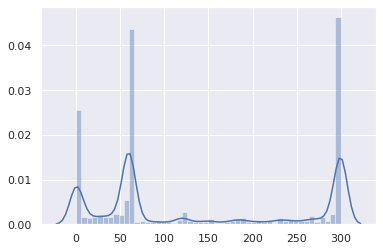
This is not great.
The cumulative distribution may make the issue even more obvious:
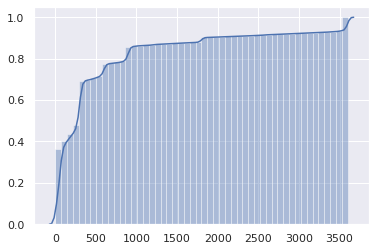
Half the DNS responses have a 1 minute TTL or less, and the three fourths have a 5 minute TTL or less.
But wait, this is actually worse. These are TTLs as defined by authoritative servers. However, TTLs retrieved from client resolvers (e.g. routers, local caches) get a TTL that upstream resolvers decrement every second.
So, on average, the actual duration a client can use a cached entry before requiring a new query is half of the original TTL.
Maybe these very low TTLs only affect uncommon queries, and not popular websites and APIs. Let’s take a look:
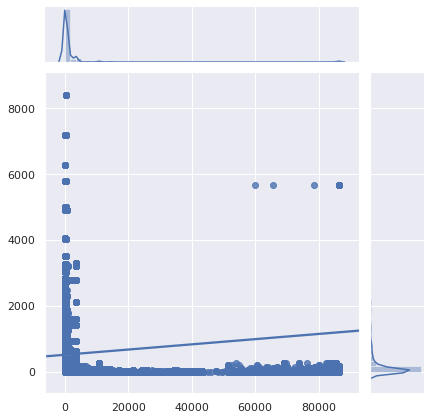
The X axis is the TTL, the Y axis is the query popularity.
Unfortunately, the most popular queries are also the most pointless to cache.
Let’s zoom in:
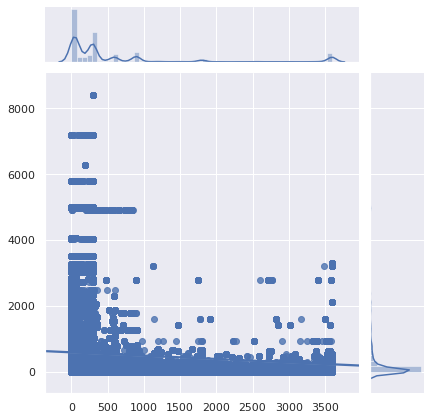
Verdict: it’s really bad. It was already bad, it got worse. DNS caching has become next to useless. With less and less people using their ISP’s DNS resolver (for good reasons), the increased latency becomes more noticeable.
DNS caching has become only useful for content no one visits.
Also note that software can interpret low TTLs differently.
Why?
Why are DNS records set with such low TTLs?
- Legacy load balancers left with default settings
- The urban legend that DNS-based load balancing depends on TTLs (it doesn’t - since Netscape Navigator, clients pick a random IP from a RR set, and transparently try another one if they can’t connect)
- Administrators wanting their changes to be applied immediately, because it may require less planning work.
- As a DNS or load balancer administator, your duty is to efficiently deploy the configuration people ask, not to make websites and services fast.
- Low TTLs give peace of mind.
- People initially use low TTLs for testing, and forget to crank them up later.
I’m not including “for failover” in that list, as this has become less and less relevant. If the intent is to redirect users to a different network just to display a fail whale page when absolutely everything else is on fire, having more than 1 minute delay is probably acceptable.
Also, a 1 minute TTL means that if authoritative DNS servers are hosed for more than 1 minute, no one would be able to access the dependant services any longer. And redundancy is not going to help if the cause is a configuration error or a hack. On the other hand, with reasonable TTLs, a good amount of clients will keep using the previous configuration and may never be affected.
CDNs and load-balancers are largely to blame for low TTLs, especially when they combine CNAME records with short TTLs with records also having short (but independent) TTLs:
$ drill raw.githubusercontent.com
raw.githubusercontent.com. 9 IN CNAME github.map.fastly.net.
github.map.fastly.net. 20 IN A 151.101.128.133
github.map.fastly.net. 20 IN A 151.101.192.133
github.map.fastly.net. 20 IN A 151.101.0.133
github.map.fastly.net. 20 IN A 151.101.64.133
A new query needs to be sent whenever the CNAME or any of the A records expire. They both have a 30 second TTL but are not in phase. The actual average TTL will be 15 seconds.
But wait! This is worse. Some resolvers behave pretty badly in such a low-TTL-CNAME+low-TTL-records situation:
$ drill raw.githubusercontent.com @4.2.2.2
raw.githubusercontent.com. 1 IN CNAME github.map.fastly.net.
github.map.fastly.net. 1 IN A 151.101.16.133
This is Level3’s resolver, which I think is running BIND. If you keep sending that query, the returned TTL will always be 1. Essentially, raw.githubusercontent.com will never be cached.
Here’s another example of a low-TTL-CNAME+low-TTL-records situation, featuring a very popular name:
$ drill detectportal.firefox.com @1.1.1.1
detectportal.firefox.com. 25 IN CNAME detectportal.prod.mozaws.net.
detectportal.prod.mozaws.net. 26 IN CNAME detectportal.firefox.com-v2.edgesuite.net.
detectportal.firefox.com-v2.edgesuite.net. 10668 IN CNAME a1089.dscd.akamai.net.
a1089.dscd.akamai.net. 10 IN A 104.123.50.106
a1089.dscd.akamai.net. 10 IN A 104.123.50.88
No less than 3 CNAME records. Ouch. One of them has a decent TTL, but it’s totally useless. Other CNAMEs have an original TTL of 60 second, the akamai.net names have a maximum TTL of 20 seconds and none of that is in phase.
How about one that your Apple devices constantly poll?
$ drill 1-courier.push.apple.com @4.2.2.2
1-courier.push.apple.com. 1253 IN CNAME 1.courier-push-apple.com.akadns.net.
1.courier-push-apple.com.akadns.net. 1 IN CNAME gb-courier-4.push-apple.com.akadns.net.
gb-courier-4.push-apple.com.akadns.net. 1 IN A 17.57.146.84
gb-courier-4.push-apple.com.akadns.net. 1 IN A 17.57.146.85
Same configuration as Firefox, and the TTL is stuck to 1 most of the time when using Level3’s resolver.
Dropbox?
$ drill client.dropbox.com @8.8.8.8
client.dropbox.com. 7 IN CNAME client.dropbox-dns.com.
client.dropbox-dns.com. 59 IN A 162.125.67.3
$ drill client.dropbox.com @4.2.2.2
client.dropbox.com. 1 IN CNAME client.dropbox-dns.com.
client.dropbox-dns.com. 1 IN A 162.125.64.3
safebrowsing.googleapis.com has a TTL of 60 second. Facebook names have a 60 second TTL. And, once again, from a client perspective, these values should be halved.
How about setting a minimum TTL?
Using the name, query type, TTL and timestamp initially stored, I wrote a script that simulates the 1.5+ million queries going through a caching resolver in order to estimate how many queries were sent due to an expired cache entry.
47.4% of the queries were made after an existing, cached entry had expired. This is unreasonably high.
What would be the impact on caching if a minimum TTL was set?
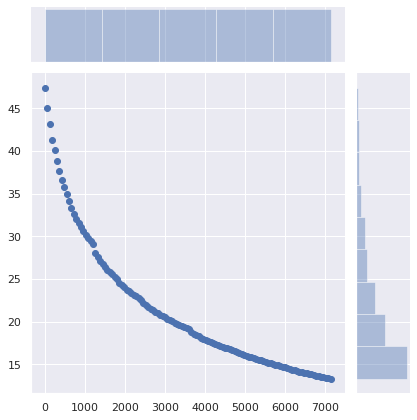
The X axis is the minimum TTL that was set. Records whose original TTL was higher than this value were unaffected.
The Y axis is the percentage of queries made by a client that already had a cached entry, but a new query was made and the cached entry had expired.
The number of queries drops from 47% to 36% just by setting a minimum TTL of 5 minutes. Setting a minimum TTL of 15 minutes makes the number of required queries drop to 29%. A minimum TTL of 1 hour makes it drop to 17%. That’s a significant difference!
How about not changing anything server-side, but having client DNS caches (routers, local resolvers and caches…) set a minimum TTL instead?
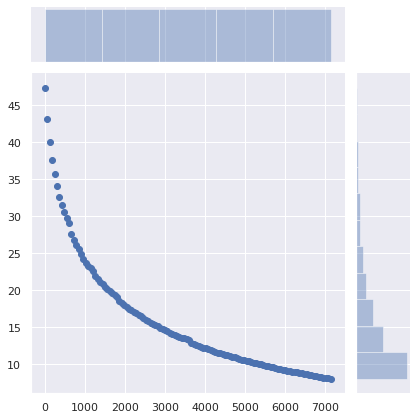
The number of required queries drops from 47% to 34% by setting a minimum TTL of 5 minutes, to 25% with a 15 minutes minimum, and to 13% with a 1 hour minimum. 40 minutes may be a sweet spot.
The impact of that minimal change is huge.
What are the implications?
Of course, a service can switch to a new cloud provider, a new server, a new network, requiring clients to use up-to-date DNS records. And having reasonably low TTLs helps make the transition friction-free. However, no one moving to a new infrastructure is going to expect clients to use the new DNS records within 1 minute, 5 minutes or 15 minutes. Setting a minimum TTL of 40 minutes instead of 5 minutes is not going to prevent users from accessing the service.
However, it will drastically reduce latency, and improve privacy and reliability by avoid unneeded queries.
Of course, RFCs say that TTLs should be stricly respected. But the reality is that DNS has become quite inefficient.
If you are operating authoritative DNS servers, please revisit your TTLs. Do you really need these to be ridiculously low?
Sure, there are valid reasons to use low DNS TTLs. But not for 75% of the DNS traffic, even though it is mostly immutable.
And if, for whatever reasons, you really need to use low DNS TTLs, also make sure that caching doesn’t work on your website either. For the very same reasons.
If you use a local DNS cache such as dnscrypt-proxy that allows minimum TTLs to be set, use that feature. This is okay. Nothing bad will happen. Set that minimum TTL to something between 40 minutes (2400 seconds) and 1 hour. This is a perfectly reasonable range.
Voila.